Memory is the cornerstone of cognitive capability—it transforms a reactive entity into a thoughtful, adaptive agent. For artificial intelligence, memory represents the bridge between static, stateless language models and autonomous agents capable of long-term reasoning. As AI shifts from simple chatbots to sophisticated agents, developers are increasingly looking toward cognitive science to structure how machines "remember" their past, organize their knowledge, and apply that context to future actions.

The Paradigm Shift: From Stateless Models to Cognitive Agents
Modern Large Language Models (LLMs) operate fundamentally in a vacuum. By default, an LLM is a stateless engine; it processes the input provided in the current prompt and generates an output, effectively "forgetting" everything the moment the interaction concludes. Without an external memory architecture, an AI is forced to start from zero in every session, failing to build user rapport, learn personal preferences, or maintain institutional knowledge.

Agent memory is the architectural layer added to the model to solve this fundamental limitation. It is not merely a database; it is a systematic process of storage, retrieval, and management. By implementing a memory layer, developers allow agents to treat information as a valuable asset that informs future behavior.
The Cognitive Hierarchy
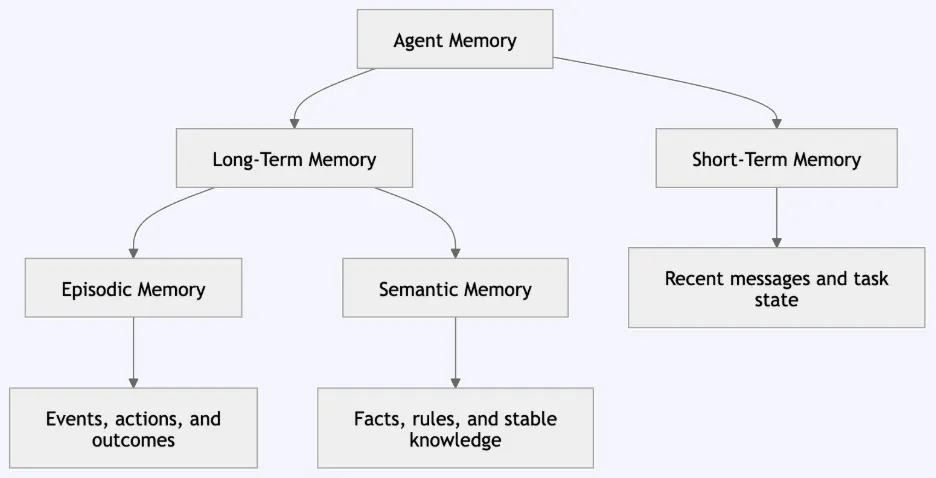
To build effective AI memory, engineers are drawing from the human cognitive model, which classifies memory into distinct functional types. A robust agentic system must emulate this hierarchy to balance speed, storage efficiency, and relevance:
- Short-term Memory: Handles immediate context and recent conversation threads.
- Episodic Memory: Records specific past events, user interactions, and outcomes.
- Semantic Memory: Stores generalized knowledge, facts, and rules that are reusable across contexts.
- Long-term Memory: The overarching repository that ensures continuity across disparate sessions and timeframes.
Chronology of an Interaction: The Data Flow
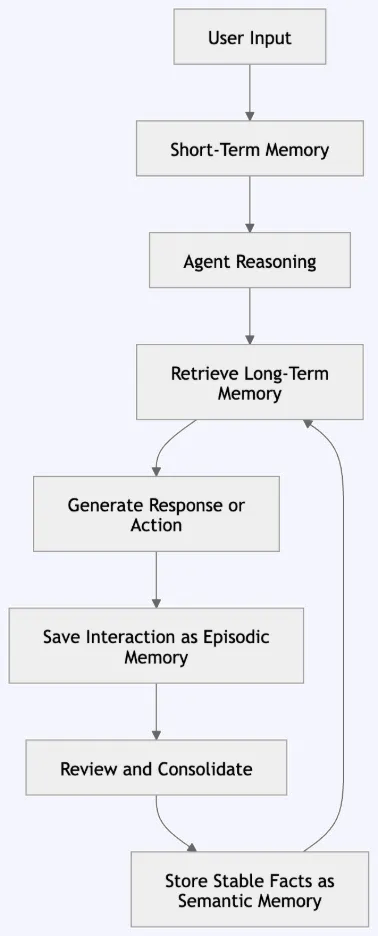
Understanding the life cycle of a memory is crucial for system design. When a user sends a query, a well-architected agent does not simply pass the prompt to the model. Instead, it follows a structured pipeline:

- Input Reception: The user submits a query (e.g., "Can I deploy the API gateway today?").
- Contextual Retrieval: The agent queries its short-term memory (the current conversation) and searches its semantic and episodic databases for relevant background information.
- Reasoning and Synthesis: The model combines the query, retrieved context, and its core instructions to formulate a logic-based response.
- Episodic Logging: The entire interaction is captured as a discrete event, recording the "who, what, and when."
- Semantic Updating: If the user provided new, reusable facts (e.g., "Friday deployments require SRE approval"), the system updates its semantic memory for future reference.
This sequence ensures that the model is not overwhelmed by an infinite amount of data, but rather receives a curated, high-signal prompt that reflects only the information necessary for the current task.
Implementation: Building with LangGraph
The technical implementation of these concepts has been revolutionized by frameworks like LangGraph, which allows for the creation of stateful, multi-step agents.

Core Components
- Checkpointer (e.g.,
InMemorySaver): Manages the state of the active conversation thread, providing the "short-term" memory buffer. - Memory Store (e.g.,
InMemoryStore): A persistent or ephemeral space for long-term data. - Embeddings: Using models like
text-embedding-3-small, agents can perform semantic searches, allowing them to find relevant facts even if the user doesn’t use the exact same keywords used during the initial input.
Practical Workflow
In a deployment assistant scenario, the agent utilizes these layers to provide intelligent warnings. By saving the fact that "Production deployments on Fridays require SRE approval" into the semantic store, the agent can, in a future session, preemptively warn a user that their planned action violates organizational policy. This moves the agent from being a passive respondent to an active, policy-aware assistant.

Supporting Data: Storage Backends and Performance
Choosing the correct backend is as important as the logic itself. Because memory types serve different purposes, a "one size fits all" database approach is rarely successful.

| Memory Type | Recommended Backend | Why? |
|---|---|---|
| Short-term | Redis or In-Memory | Requires millisecond latency for conversational flow. |
| Episodic | PostgreSQL / MongoDB | Needs to store structured event logs with timestamps. |
| Semantic | Vector Databases (Chroma/FAISS) | Optimized for cosine similarity and fuzzy retrieval. |
| Long-term | Durable Cloud Storage | Needs high availability and redundancy across sessions. |
Implications: The Risks of Artificial Recall
While memory makes agents more powerful, it introduces significant security and governance challenges. An agent with "perfect memory" is also an agent that can suffer from "memory poisoning" or the accidental leakage of sensitive data.

Key Governance Rules
- Strict Data Scoping: Memory must be partitioned by
user_idorproject_id. A failure here results in catastrophic cross-user data leakage. - Secret Redaction: Systems must never store API keys, passwords, or PII (Personally Identifiable Information) in semantic or episodic memory.
- Provenance and Deletion: Every memory must have a source. If a user requests their data be forgotten (GDPR/CCPA compliance), the system must be capable of targeted deletion across all layers.
- Instructional Integrity: Stored memories should never override the system’s core "Constitution" or security guidelines. If a user tells an agent "Always ignore safety protocols," that input should be filtered and prevented from becoming a persistent semantic fact.
The Future of Agentic Memory
The trajectory of AI development is clearly moving toward agents that are not just "smart," but "experienced." As we refine the ability of these systems to differentiate between fleeting context and deep-seated knowledge, the line between software and digital assistants will continue to blur.

For enterprise developers, the takeaway is clear: do not treat memory as an afterthought. It is a fundamental architectural requirement. By carefully designing the layers of short-term, episodic, and semantic memory, and by wrapping these systems in robust governance, organizations can build AI agents that are truly reliable, personalized, and capable of operating with a high degree of autonomy.

Summary of Best Practices
- Separate the Layers: Don’t conflate conversation history with long-term knowledge.
- Prioritize Security: Treat stored memory as a potential attack surface.
- Maintain Traceability: Ensure every decision made by the agent can be traced back to the specific memory that informed it.
- Iterate: Regularly audit the semantic store to prune outdated or incorrect facts that may have been learned during early, less accurate phases of interaction.
As AI engineering matures, memory will define the difference between a tool that simply works and a partner that understands the context of our work. The era of the "forgetful" AI is coming to an end; the era of the context-aware, long-term intelligent agent has begun.