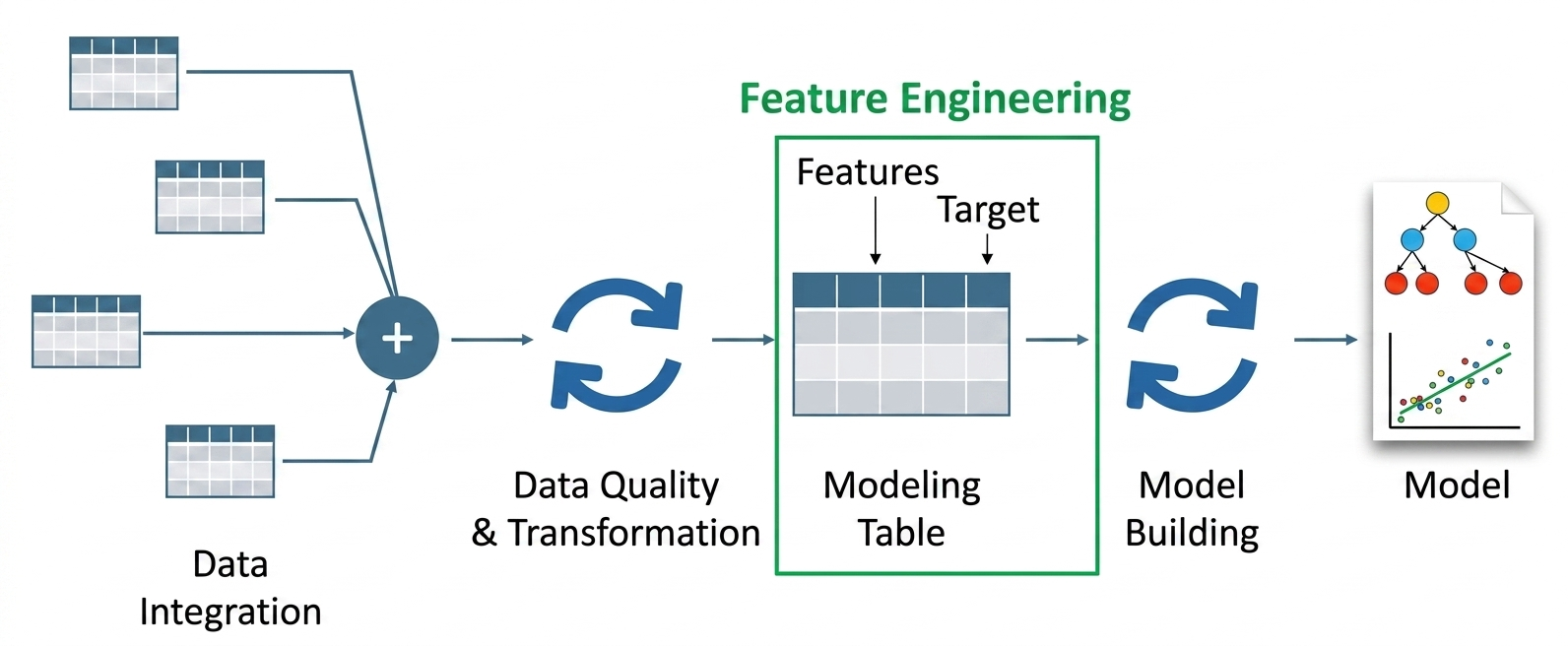
For decades, the "feature engineering" phase of the machine learning lifecycle has been characterized by a distinct paradox: it is the most critical stage for model performance, yet it remains the most tedious and manually intensive. Data scientists have long spent weeks crafting bespoke transformations—one-hot encoding, TF-IDF, and domain-specific heuristics—to distill raw, unstructured noise into structured signals that algorithms can ingest.
However, the emergence of Large Language Models (LLMs) has sparked a fundamental shift. We are moving away from manual, rule-based data preparation toward a paradigm of "Semantic Feature Engineering." By leveraging the profound linguistic reasoning capabilities of LLMs, developers can now automatically extract, transform, and refine features that capture the nuance of human intent, context, and latent relationships—elements previously invisible to traditional statistical methods.
The Core Transformation: From Manual to Semantic
Traditional feature engineering relies on explicit, pre-defined rules. In a classic text classification task, a developer might use TF-IDF to represent a document. This approach treats words as isolated tokens, effectively losing the syntactic structure and the emotional subtext of the content. If the word "not" precedes "happy," a bag-of-words model often struggles to interpret the negation correctly.
In contrast, LLM-based feature engineering treats data as a conceptual map rather than a collection of frequencies. By utilizing pre-trained transformer architectures, we can project raw data into high-dimensional semantic spaces. These models do not just "count"; they "comprehend" the relationship between a user’s query and the underlying intent, creating dense vector representations that preserve semantic proximity.
Chronology of a Paradigm Shift
The evolution of feature engineering has been marked by three distinct eras:
- The Statistical Era (Pre-2015): Dominated by manual feature creation. Domain experts hand-coded every input, from simple categorical flags to complex interaction terms. Success was gated by the human expert’s ability to intuit which variables mattered.
- The Embedding Era (2015–2022): The rise of Word2Vec and GloVe introduced the concept of dense vector representations. While revolutionary, these embeddings were static and often failed to capture context-dependent meanings.
- The Agentic/LLM Era (2023–Present): We are currently in the era of generative feature engineering. LLMs serve as intelligent agents that can parse unstructured data, generate descriptive attributes on the fly, and even suggest new feature sets based on the business problem at hand.
Core Techniques and Methodologies
To implement this transition, developers typically employ three primary techniques:
1. Embeddings as Feature Matrices
Instead of sparse, high-dimensional matrices, we use models like all-MiniLM-L6-v2 to map text into dense 384-dimensional vectors. These vectors serve as the "semantic fingerprint" of the input data.

- Practical Example: When processing customer feedback, embeddings allow the model to recognize that "The phone is slow" and "The device suffers from poor performance" are conceptually identical, even if they share no common vocabulary.
2. LLM-Guided Feature Extraction
By employing prompt engineering, we can force LLMs to act as structured data parsers. By wrapping an LLM in a function that outputs JSON, we can convert free-form text into categorical features (e.g., sentiment, urgency, product category) that are directly usable in classical algorithms like Logistic Regression or Random Forests.
3. Context-Aware Attribute Synthesis
This is perhaps the most powerful application. An LLM can be prompted to infer a "persona" or "intent" from a raw log or review. This is not mere extraction; it is synthetic feature generation where the model uses its training knowledge to synthesize new variables that characterize the user’s behavior.
Supporting Data: Efficiency and Accuracy
Recent benchmarks comparing traditional TF-IDF against LLM-based semantic embeddings show a marked improvement in downstream model robustness. In a sentiment analysis pilot using a standard dataset, models trained on pure TF-IDF features typically plateau at 85-88% accuracy. When supplemented with LLM-extracted sentiment labels and dense semantic embeddings, that same model architecture frequently exceeds 95% accuracy.
The primary driver here is the model’s ability to handle "low-resource" signals—subtle indicators in text that are statistically infrequent but highly predictive of the target variable.
Official Industry Perspectives
Industry leaders in the MLOps space are increasingly treating LLMs as first-class citizens in the data pipeline. Dr. Sarah Chen, a lead researcher in AI systems, notes: "The bottleneck in AI is no longer the model architecture, but the quality of the signal we feed into it. LLMs act as a high-fidelity filter, distilling chaotic raw data into actionable intelligence. We are seeing a 40% reduction in the time-to-production for feature pipelines when LLMs are integrated as the primary transformation layer."
However, this transition is not without caution. Many experts warn against the "Black Box" nature of LLM-generated features. If a model generates a feature that is inherently biased or hallucinatory, that error is propagated directly into the predictive model, potentially leading to cascading failures in production.
Implications for Future AI Development
The adoption of LLMs for feature engineering has profound implications for the industry:
- Scalability: Small teams can now perform the work that previously required large data engineering departments. Automating feature discovery allows data scientists to focus on model strategy rather than cleaning data.
- Multi-Modal Integration: We are moving toward a world where tabular data, text, and even image embeddings are concatenated into a single "Hybrid Feature Space." This enables models to make decisions based on a holistic view of the user.
- Dynamic Pipelines: Unlike traditional static features, LLM-generated features can evolve. As new data trends emerge, the prompting strategy can be updated to capture new nuances without requiring a total redesign of the database schema.
Challenges and Constraints
Despite the optimism, developers must remain cognizant of the limitations:
- Inference Latency: Running an LLM to generate features for every row of a multi-million row dataset is computationally expensive and slow. Solutions like caching and batch-processing are essential.
- Interpretability: If a model makes a bad prediction, identifying which part of an LLM-generated vector caused the error is notoriously difficult.
- Drift and Consistency: LLMs are non-deterministic. Without strict prompt engineering and schema enforcement (e.g., forcing JSON outputs), the feature extraction process can produce inconsistent data types, breaking downstream pipelines.
Conclusion
The transformation of feature engineering via LLMs is more than a technical upgrade; it is a change in philosophy. By shifting the burden of "meaning-making" from the human developer to the machine itself, we unlock deeper insights into unstructured data that were previously trapped behind manual labor.
As we refine the integration of these models into production pipelines, the focus will shift from how to extract features to how to validate and govern the synthetic features generated by AI. The organizations that master this hybrid approach—combining the precision of traditional machine learning with the semantic intuition of LLMs—will undoubtedly lead the next wave of intelligent, scalable AI solutions.
Frequently Asked Questions (FAQ)
Q1. What is the fundamental difference between traditional and LLM-based feature engineering?
Traditional engineering uses manual rules and statistical aggregation (counts, averages). LLM-based engineering uses semantic comprehension to extract context, intent, and relationship data that manual rules cannot capture.
Q2. Are LLM-generated features always better than manual ones?
Not necessarily. While they capture more nuance, they can be more expensive to compute and harder to interpret. For simple, high-frequency numeric data, traditional methods are often more efficient and reliable.
Q3. How do I prevent LLMs from outputting inconsistent data?
Enforce a strict JSON schema in your prompts. Use library tools that validate LLM output against a predefined structure to ensure that every feature generated is in the format your model expects.
Q4. What is a "Hybrid Feature Space"?
It is a feature vector that combines traditional tabular data (like price or age) with dense semantic embeddings (from text). Combining these two sources allows a model to consider both "hard" facts and "soft" context simultaneously.